Last Updated: 2022-09-28
What you will build
In this codelab, you will port a small Fortran application to GPU hardware using OpenMP. You will transition a serial CPU-only mini-application to a portable GPU accelerated application, using OpenMP provided through the AOMP compiler.
The goal of this codelab is to introduce you to using a few basic OpenMP directives and a development practice that can be applied to porting other applications.
What you will learn
- How to develop a GPU porting strategy using application profiles and call graphs.
- How to manage GPU memory with OpenMP.
- How to launch GPU accelerated kernels with OpenMP.
- How to build GPU accelerated Fortran applications for AMD and Nvidia platforms.
- How to verify GPU memory allocation and kernel execution with the rocprof profiler.
What you will need
- A compute platform with AMD or Nvidia GPU(s)
- CUDA Toolkit 10 or greater (Nvidia platforms only)
- ROCm (v4.2 or greater)
- Fortran compiler
The demo application provided for this tutorial performs 2-D smoothing operations using a 3x3 gaussian stencil.
In this section, we introduce the demo application and walk through building and verifying the example. It's important to make sure that the code produces the expected result as we will be using the CPU generated model output to ensure that the solution does not change when we port to the GPU.
This application executes a 2-D smoothing operation on a square grid of points. The program proceeds as follows
- Process command line arguments
- Allocate memory for smoother weights (Gaussian), a function, and the smoothed function
- Initialize function on CPU and report function to file
- Call smoothing function
- Report smoothed function to file
- Clear memory
Code Structure
This application's src directory contains the following files
smoother.F90: A module that defines the routines needed to apply the smoothing operation and update the function with each iterate.main.F90: Defines the main program that sets up the 2-D field to be smoothed and managed file IO.makefile: A simple makefile is to build the application binarysmoother.viz.py: A python script for creating plots of the smoother output
Install and Verify the Application
To get started, we want to make sure that the application builds and runs on your system using the gcc compiler.
- Clone the repository
$ git clone https://github.com/fluidnumerics/scientific-computing-edu ~/scientific-computing-edu- Build the smoother application. Keep in mind, the compiler is set to gcc by default in the provided makefile.
$ cd samples/fortran/smoother/src
$ make- Test run the example. The application takes three arguments. The first two arguments are the number of grid cells in the x and y dimensions. The third argument is the number of times the smoothing operator is applied. Running the example below smooths data on a 1000x1000 grid using 10 sweeps of the Gaussian smoother.
$ ./smoother 1000 1000 10
Profile the Application
Before starting any GPU porting exercise, it is important to profile your application to find hotspots where your application spends most of its time. Further, it is helpful to keep track of the runtime of the routines in your application so that you can later assess whether or not the GPU porting has resulted in improved performance. Ideally, your GPU-Accelerated application should outperform CPU-Only versions of your application when fully subscribed to available CPUs on a compute node.
Create the profile
In this tutorial, we are going to generate a profile and call graph using gprof. The provided makefile was already configured to create profile output. From here, you just need to use gprof to create the application profile.
$ gprof ./smoother gmon.outInterpret the profile and call tree
gprof provides a flat profile and a summary of your application's call structure indicating dependencies within your source code as a call tree. A call tree depicts the relationships between routines in your source code. Combining timing information with a call tree will help you plan the order in which you port routines to the GPU.
The first section of the gprof output is the flat-profile. An example flat-profile for the smoother application is given below. The flat-profile provides a list of routines in your application, ordered by the percent time your program spends within those routines from greatest to least. Beneath the flat-profile, gprof provides documentation of each of the columns for your convenience.
% cumulative self self total
time seconds seconds calls s/call s/call name
97.67 11.50 11.50 100 0.11 0.11 __smoother_MOD_applysmoother
2.30 11.77 0.27 100 0.00 0.00 __smoother_MOD_resetf
0.17 11.79 0.02 1 0.02 11.79 MAIN__
0.00 11.79 0.00 3 0.00 0.00 __smoother_MOD_str2int
0.00 11.79 0.00 1 0.00 0.00 __smoother_MOD_getcliconfLet's now take a look at at the call tree. This call tree has five entries, one for each routine in our program. The right-most field for each entry indicates the routines that called each routine and that are called by each routine.
For smoother, the first entry shows that main calls ApplySmoother, resetF, and getCLIConf. Further, the called column indicates that ApplySmoother and resetF routines are shown to be called 100 times (in this case) by main. The self and children columns indicate that main spends 0.02s executing instructions in main and 11.77s in calling other routines. Further, of those 11.77s, 11.50s are spent in ApplySmoother and 0.27 are spent in resetF.
index % time self children called name
0.02 11.77 1/1 main [2]
[1] 100.0 0.02 11.77 1 MAIN__ [1]
11.50 0.00 100/100 __smoother_MOD_applysmoother [3]
0.27 0.00 100/100 __smoother_MOD_resetf [4]
0.00 0.00 1/1 __smoother_MOD_getcliconf [12]
-----------------------------------------------
<spontaneous>
[2] 100.0 0.00 11.79 main [2]
0.02 11.77 1/1 MAIN__ [1]
-----------------------------------------------
11.50 0.00 100/100 MAIN__ [1]
[3] 97.5 11.50 0.00 100 __smoother_MOD_applysmoother [3]
-----------------------------------------------
0.27 0.00 100/100 MAIN__ [1]
[4] 2.3 0.27 0.00 100 __smoother_MOD_resetf [4]
-----------------------------------------------
0.00 0.00 3/3 __smoother_MOD_getcliconf [12]
[11] 0.0 0.00 0.00 3 __smoother_MOD_str2int [11]
-----------------------------------------------
0.00 0.00 1/1 MAIN__ [1]
[12] 0.0 0.00 0.00 1 __smoother_MOD_getcliconf [12]
0.00 0.00 3/3 __smoother_MOD_str2int [11]
-----------------------------------------------Next steps
Now that we have a profile and an understanding of the call structure of the application, we can now plan our port to GPUs. First, we will focus on porting the ApplySmoother routine and the necessary data to the GPU, since ApplySmoother takes up the majority of the run time.
When we port this routine, we will introduce data allocation on the GPU and data copies between CPU and GPU. This data movement may potentially increase the overall application runtime, even if the ApplySmoother routine performs better. In this event, we will then work on minimizing data movements between CPU and GPU.
Before jumping straight into GPU offloading with OpenMP, you will take an incremental step to change the compiler and verify the application can be compiled and executed with the amdflang compiler. Once this is verified, you will then start the GPU offloading process.
ROCm comes with compilers ( amdflang, amdclang, and amdclang++ ) that support the OpenMP 4.5 standard or greater. To enable GPU offloading at compile time, there are a few flags that you need to pass to the compiler.
amdflang -fopenmp \
-fopenmp-targets=[target] \
-Xopenmp-target=[target] \
-march=[gpu-arch]
[other options]
[source-code]
In this example,
[target]is one ofamdgcn-amd-amdhsaornvptx64-nvidia-cuda[gpu-arch]is the GPU architecture code. For MI100 GPUs,[march]=gfx908and for V100 GPUs,[march]=sm_72.
ROCm also comes with a helpful tool (mygpu) that can be used to detect the GPU architecture. This is particularly useful if you are building the code on a machine that has the GPU you want to build for.
In this section, you will make the following changes to the Makefile
- Change the default Fortran compiler to amdflang
- Use the
mygpubinary to set the GPU architecture and target - Append the required OpenMP flags to FFLAGS
- Starting from the
smoothermakefile (samples/fortran/smoother/src/Makefile), Let's first add variables for the paths to ROCm and CUDA at the top of the file. These will be needed to reference full paths to the compiler andmygpubinary.
When setting these variables, we use the ?= relation to allow a user's environment variables to override these values if desired.
ROCM ?= /opt/rocm
CUDA ?= /usr/local/cuda- Next, change the specification for the Fortran compiler, by setting FC ?= $(ROCM)/bin/amdflang . The first three lines of your Makefile should look like this :
ROCM ?= /opt/rocm
CUDA ?= /usr/local/cuda
FC ?= $(ROCM)/bin/amdflang- In ROCm 4.5.0, it is necessary to remove the -g flag from the FFLAGS definition in the Makefile.
FFLAGS = -O0
- Let's now work on a section for detecting the GPU architecture. The mygpu utility can be used to detect a GPU, if one is present. The -d flag is used to set the default architecture to fall back to in case a GPU is not present.
For example,mygpu -d gfx908will check for a GPU and return gfx908 if one is not found. In the make system, we want to also allow for someone building the code to specify the target architecture, in case they are on a system that does not have a GPU equipped.
Add the following section of code to your Makefile just beneath the definition ofFC. This section setsGPU_ARCHto the output ofmygpu -d gfx908, if it is not set in the user's environment. The-d gfx908flag indicates that the default GPU architecture will be set togfx908, if one is not found on the system you are building on.
# Detect the GPU architecture
GPU_ARCH ?= $(shell $(ROCM)/bin/mygpu -d gfx908)- Now that we have the GPU architecture, we can set the GPU target. Nvidia GPU architectures are all defined with a prefix of sm_ . We can use this with the
findstringfunction to set the GPU target accordingly.
Add the following section of code to your Makefile just beneath the definition ofGPU_ARCH. This section sets theGPU_TARGETvariable tonvptx64-nvidia-cudawhen an Nvidia GPU is detected andamdgcn-amd-amdhsaotherwise. Additionally, this appends the CUDA runtime library toLFLAGSin the event that you are building for an Nvidia platform.
ifeq (sm_,$(findstring sm_,$(GPU_ARCH)))
GPU_TARGET = nvptx64-nvidia-cuda
LFLAGS += -L$(CUDA)/targets/x86_64-linux/lib -lcudart
else
GPU_TARGET = amdgcn-amd-amdhsa
endif- Now you can append the OpenMP offload flags to the
FFLAGSvariable. Just beneath theGPU_TARGETdefinition, add the following code to append to theFFLAGSvariable.
FFLAGS += -fopenmp -fopenmp-targets=$(GPU_TARGET) -Xopenmp-target=$(GPU_TARGET) -march=$(GPU_ARCH)Verify the application compiles and runs
Now that you have made the necessary modifications to the Makefile, it is time to re-compile and test the application. You also want to make sure that the application output is unchanged.
- On your first run of the smoother application, two files were created : function.txt and smooth-function.txt . You will use these to verify that the code still produces the same output.
Copy the existing output from your previous run to a reference directory.
$ mkdir reference
$ cp function.txt smooth-function.txt reference/- Re-compile the
smootherapplication.
$ make clean
$ make- Run the
smootherapplication with the same input parameters as before and compare the output with the reference output. You can use the diff command line tool to compare the new output with the reference output. If the files are identical, no output will be printed to screen.
$ time ./smoother 1000 1000 100
real 0m21.750s
user 0m21.469s
sys 0m0.172s
$ diff function.txt reference/function.txt
$ diff smooth-function.txt reference/function.txtNext Steps
Now that you've switched to using the amdflang compiler and have verified the application successfully compiles and runs and produces the correct output, you are ready to begin offloading to GPUs with OpenMP. In the next step, you will offload the ApplySmoother and resetF routines using OpenMP directives.
In the smoother application, we have seen that the ApplySmoother routine, called by main, takes up the most time. Within the main iteration loop in main.cpp, the resetF function is called to update the input for smoother for the next iteration.
You will start by offloading both the ApplySmoother and resetF routines to the GPU using OpenMP directives (also called "pragmas"). In this section you will learn how to offload sections of code to the GPU and how to manage GPU data using OpenMP pragmas.
Offload ApplySmoother
- Open
smoother.F90and navigate to theApplySmootherroutine. Open an OpenMP target region before the start of the first loop inApplySmootherand map the necessary map directives to copysmoother->weightsandfto the GPU andsmoothFto and from the GPU.
!$omp target map(to:weights, f) map(smoothF)- Use a
teams distribute parallel dodirective with acollapse(2)clause to parallelize the outer two loops.
!$omp target map(to:weights, f) map(smoothF)
!$omp teams distribute parallel do collapse(2) thread_limit(256)
DO j = 1+nW, nY-nW
DO i = 1+nW, nX-nW
! Take the weighted sum of f to compute the smoothF field
smoothF(i,j) = 0.0_prec
DO jj = -nW, nW
DO ii = -nW, nW
smoothF(i,j) = smoothF(i,j) + f(i+ii,j+jj)*weights(ii,jj)
ENDDO
ENDDO
ENDDO
ENDDO
!$omp end target- Re-compile the
smootherapplication.
$ make- Run the
smootherapplication with the same input parameters as before and compare the output with the reference output. You can use the diff command line tool to compare the new output with the reference output. If the files are identical, no output will be printed to screen.
$ ./smoother 1000 1000 100
$ diff function.txt reference/function.txt
$ diff smooth-function.txt reference/function.txtOffload ResetF
- Open
smoother.F90and navigate to theResetFroutine. Open an OpenMPtargetregion before the start of the first loop inResetFand map the necessary map directives to copysmoothFto the GPU andfto and from the GPU.
!$omp target map(to:smoothF) map(f)- Use a
teams parallel dodirective with acollapse(2)clause to parallelize the outer two loops.
!$omp target map(to:smoothF) map(f)
!$omp teams distribute parallel do collapse(2)
DO j = 1+nW, nY-nW
DO i = 1+nW, nX-nW
f(i,j) = smoothF(i,j)
ENDDO
ENDDO
!$omp end target- Re-compile the
smootherapplication.
$ make- Run the
smootherapplication with the same input parameters as before and compare the output with the reference output. You can use the diff command line tool to compare the new output with the reference output. If the files are identical, no output will be printed to screen.
$./smoother 1000 1000 100
$ diff function.txt reference/function.txt
$ diff smooth-function.txt reference/function.txt- To profile, you can profile the application using the rocprof profiler. If you would like to create a trace profile, add the
--hsa-trace --obj-tracking on flags. If you would like to get a summary hotspot profile of the GPU kernels, use the--statsflag.
$ rocprof --hsa-trace --obj-tracking on --stats ./smoother 1000 1000 10
$ cat results.stat.csv
"Name","Calls","TotalDurationNs","AverageNs","Percentage"
"__omp_offloading_801_440b81_ApplySmoother_l67.kd",10,30603997,3060399,78.4420113965
"__omp_offloading_801_440b81_resetF_l48.kd",10,8410807,841080,21.5579886035Next steps
You've successfully offloaded two routines to the GPU. However, you may have noticed that the runtime did not improve much, and may have even gotten worse, after you offloaded the second routine (resetF). At the start and end of each target region, the application is copying data between the CPU and GPU. You can see this behavior in the trace profile shown above. Ideally, you want to minimize data movement between the host and device.
In the next section, you will learn how to control when data is allocated and moved to and from the GPU. This will help you minimize data copies between the host and device that often become bottlenecks for GPU accelerated applications.
In this section you will learn how to use unstructured data directives with OpenMP to control when data is copied to and from the GPU.
In the smoother application, there are two routines within a main iteration loop, ApplySmoother and resetF. Both routines operate on data stored in two arrays, f and smoothF.
DO iter = 1, nIter
CALL ApplySmoother( f, weights, smoothF, nW, nX, nY )
CALL ResetF( f, smoothF, nW, nX, nY )
ENDDOAdditionally, the ApplySmoother routine requires the weights array in order to calculate smoothF from f. Currently, target regions within ApplySmoother and resetF copy these arrays to and from the GPU, before and after executing the routine instructions in parallel on the GPU; this is also done every iteration.
OMP Enter/Exit Data
Ideally, we want to have all of the necessary data copied to the GPU before the iteration loop and have smoothF copied from the GPU after the iteration loop. This can be achieved using the target enter data and target exit data directives.
Each directive is a standalone directive that can be used to allocate or deallocate memory on the GPU and copy data to or from the GPU. A typical usage is to use the target enter data directive to allocate device memory after allocation on the host and to use the target exit data directive to free device memory before freeing memory on the host. Then, you can use the target update directive to manage updating host and device data when needed.
In this example below, the enter data directive is used to allocate device memory for arrayIn and arrayOut. Before reaching the main block of code, the target update directive is used to update arrayIn on the device. At the end of this region of code, the target update directive is used to update arrayOut on the host. At the end of the example code, the exit data directive is used to free device memory before freeing the associate host pointer.
IMPLICIT NONE
INTEGER, PARAMETER :: N = 1000
REAL, ALLOCATABLE :: arrayIn(:)
REAL, ALLOCATABLE :: arrayOut(:)
ALLOCATE(arrayIn(1:N), arrayOut(1:N))
!$omp target enter data map(alloc: arrayIn, arrayOut)
! Initialization routines
.
.
! End Initialization routines
!$omp target update to(arrayIn)
!$omp teams distribute parallel do num_threads(256)
DO i = 1, N
arrayOut(i) = 2.0*arrayIn(i)
ENDDO
!$omp target update from(arrayOut)
!$omp target exit data map(delete: arrayIn, arrayOut)
DEALLOCATE(arrayIn, arrayOut)Transition to enter/exit data directives
In the smoother application, we want to explicitly control data movement for f, smoothF, and weights. You will work in main.F90 to insert calls to allocate, update, and deallocate device memory for all three of these arrays.
- Open main.F90 and find where
f,smoothF, andweightsare allocated. Just after theALLOCATEcalls, add atarget enter datadirective to allocate device memory forfand smoothF.
ALLOCATE( f(1:nX,1:nY), smoothF(1:nX,1:nY), weights(-nW:nW,-nW:nW) )
!$omp target enter data map(alloc: f, smoothF, weights)- Add a
target update todirective to copyf,smoothF, andweightsdata to the GPU just before the main iteration loop and add atarget update fromdirective to copysmoothFfrom the GPU just after the main iteration loop.
!$omp target update to(f, smoothF, weights)
DO iter = 1, nIter
CALL ApplySmoother( f, weights, smoothF, nW, nX, nY )
CALL ResetF( f, smoothF, nW, nX, nY )
ENDDO
!$omp target update from(smoothF)- Add a
target exit datadirective to deallocate device memory held byf,smoothF, andweightsbefore callingDEALLOCATEat the end ofmain.F90.
!$omp target exit data map(delete: f, smoothF, weights)
DEALLOCATE( f, smoothF, weights )- Re-compile the
smootherapplication.Run thesmootherapplication with the same input parameters as before and compare the output with the reference output. You can use the diff command line tool to compare the new output with the reference output. If the files are identical, no output will be printed to screen.
$ make
$./smoother 1000 1000 100
$ diff function.txt reference/function.txt
$ diff smooth-function.txt reference/function.txt- Profile the application using the rocprof profiler with the
--hsa-trace --obj-tracking onflags enabled. (Optionally) Open the results.json trace profile using Chrome Trace (navigate to chrome://tracing in the Google Chrome browser). Notice that, this time,ResetFis called immediately afterApplySmootherand data transfers between the CPU and GPU only occur at the beginning and end of the application run.
$ rocprof --hsa-trace --obj-tracking on ./smoother 1000 1000 100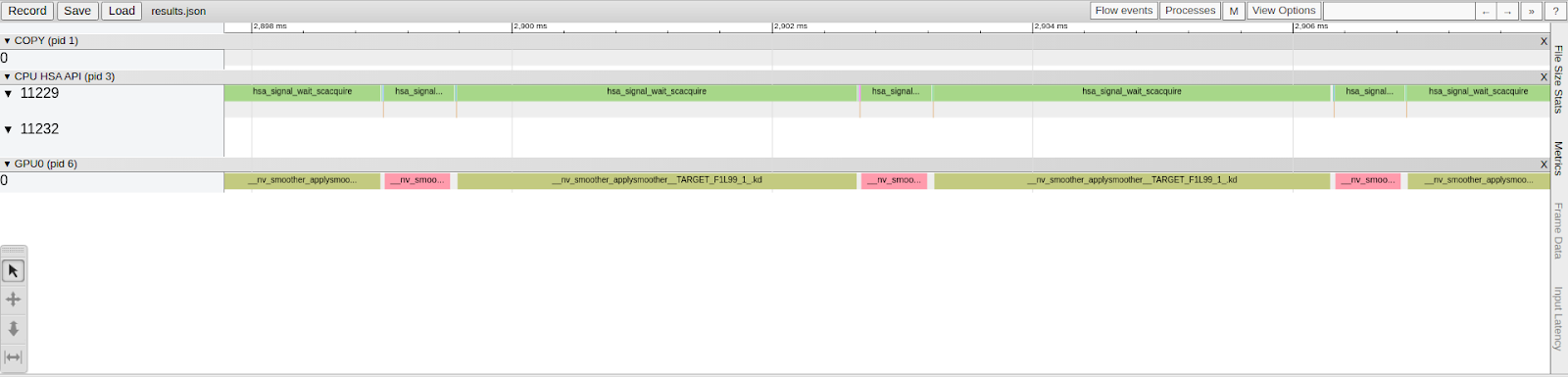
In this codelab, you learned how to port serial CPU-only routines in Fortran to GPUs using OpenMP. To do this, you used target directives to offload regions of code to the GPU. You used teams parallel for directives to parallelize nested loops across teams of GPU threads.
To reduce data copies between host and device, you applied unstructured OpenMP data directives to explicitly manage when memory is allocated/deallocated on the GPU and when data is copied between to and from the GPU.
In the process of doing this, you practiced a strategy for porting to GPUs that included the following steps to make incremental changes to your own source code :
- Profile - Find out the hotspots in your code and understand the dependencies with other routines
- Plan - Determine what routine you want to port and what data needs to be copied to and from the GPU.
- Implement & Verify - Insert the necessary OpenMP directives, compile the application, and verify the results.
- Commit - Once you have verified correctness and the expected behavior, commit your changes and start the process over again.
Provide Feedback
If you have any questions, comments, or feedback that can help improve this codelab, you can reach out to support@fluidnumerics.com